We tested our data with 10-fold cross validation on Weka, and analyzed various machine learning algorithms using the scikit-learn module on Python with SciPy, NumPy, and matplotlib.
Because of the nature of our data, we yielded our highest accuracy numbers the DTNB classifier. For any given team and week, one of the most important attributes to consider was the team's opponent. However, 93% of our non-classifier data attributes were numerical. Because the optimal classification occurred by examining one categorical attribute and numerous numerical attributes, DNTB's were very well-suited for our project.
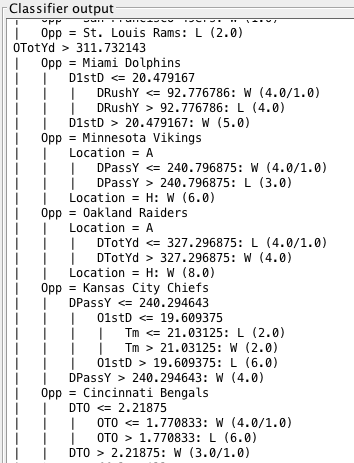
Note that for J48, Opponent is one of the first splits, and then different numerical attributes are considered given each opponent.

|
|
